Torch Matrix Multiplication On Gpu
The results presented in this paper show that the. Dot tensor_1 tensor_2 d_product.
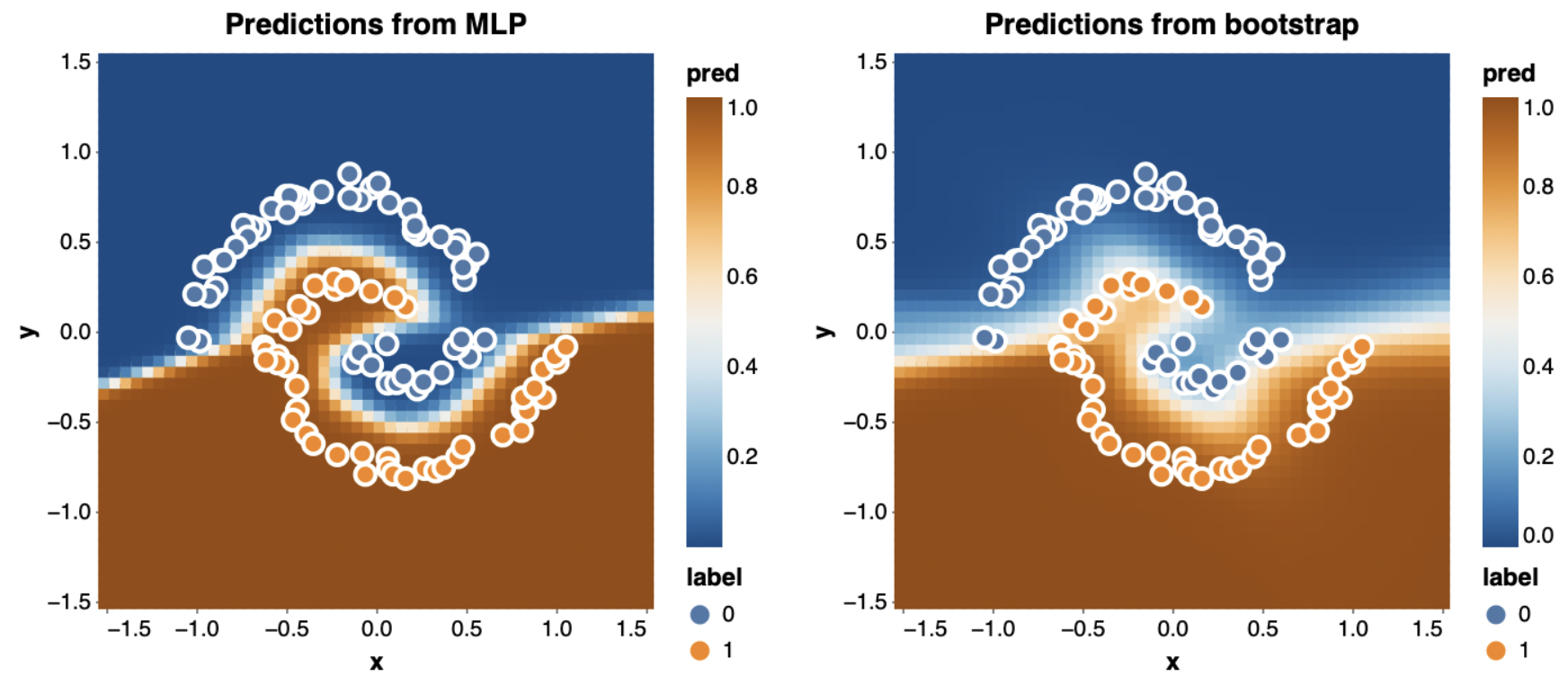
Parallelizing Neural Networks On One Gpu With Jax Will Whitney
This does not support broadcasting.
Torch matrix multiplication on gpu. Id like to be able to perform a matrix multiplication in GPU when using dtype torchuint8. The behavior depends on the dimensionality of the tensors as follows. We can multiply a tensor with a scalar.
This method provides batched matrix multiplication for the cases where both the matrices to be multiplied are of only 3-Dimensions xyz and the first dimension x of both the matrices must be same. Simple wrapper to torchmatmul for an input matrix mathbfA. Ntg ncg-nct use AX2 and for BX1 in gemmStridedBatched and pass transAfalse transBtrue.
As far as Im aware INT8 GPU matrix multiplication is already supported for CUDA and cuBLAS but Im not sure if it is competitive with using half precision. We compare matrix multiplication with size 10000x10000. Import torch a torchrandn 100128128 b torchrandn 100128128 import time t0 timetime torchbmm ab print timetime - t0 003233695030212402.
If you have access to a GPU there are potentially huge gains to be made by migrating your scientific computation over from Numpy. To avoid the hazzle of creating torchsparse_coo_tensor this package defines operations on sparse tensors by simply passing index and value tensors as arguments with same shapes as defined in PyTorch. Very low seems to be 15 and below.
A acuda b bcuda t0 timetime torchbmm ab print timetime -. Numpy Matrix Multiplication we can convert a matrix to an numpy matrix such that we can perform matrix calculation as simple as doing number calculation. Thus what you need to do is.
We can perform a dot product between two tensors as well. Torchbmm Tensor_1 Tensor_2 deterministicfalse outNone. Now if i do the same thing on GPU it takes a lot longer.
A current alternative is to use float32 or float16 dtypes. Matrix multiplication algorithm that exploits this memory. Pylops_gpuMatrixMult class pylops_gpuMatrixMult A dimsNone devicecpu togpuFalse False tocpuFalse False dtypetorchfloat32 source Matrix multiplication.
GPU implementation with the use of shared memory is two times faster than the implementation that uses. Sparse Sparse Matrix Multiplication All included operations work on varying data types and are implemented both for CPU and GPU. PyTorch also outperformed Numpy running on the CPU so even if you dont have access to a GPU there are still gains to be had.
Notably torchfloat16 seems to work if you adjust testpy to just repeatedly do float16 matrix multiplications however float32 and float64 immediately have problems. Nct ncp- ntp use AX1 and for BX2 in. Matrix product of two tensors.
If the first argument is 1-dimensional and the second argument is 2-dimensional a 1 is prepended to its dimension for the purpose of the matrix multiply. The syntax is as given below. For example when running this test with a Quadro RTX 6000 it works as expected.
The above code snippet will give us. One of the key selling points of deep learning frameworks such as Pytorch and K e ras is their deployability on GPUs which massively speeds up computation. 2 dense matrices always multiply faster than a sparse and dense matrix unless the sparse matrix has very low density.
When we put the. If both arguments are 2-dimensional the matrix-matrix product is returned. The key finding from part 1 was.
Comparing the speed using NumPy CPU and torch CPU torch performs more than twice better than NumPy 265s vs 572s. This will give us. Torchmatmulinput other outNone Tensor.
Bal memory and up to 75 times faster than the CPU implementation. Above code snippet will provide us with the following output. If both tensors are 1-dimensional the dot product scalar is returned.
Matrix1 generate_numpy_matrix3 4 matrix2 generate_numpy_matrix4 5 printthe result of matrix1 print matrix1 print printthe result of matrix2 print. However if you run this exact same test on other GPUs it will work perfectly. PyTorch on the GPU is the fastest in all six of the tests often by many orders of magnitude.
If you would like to send a tensor to your GPU you just need to do a simple cuda CPU to GPU device torchdevicecuda0 if torchcudais_available else cpu tensor_cputodevice And if you want to move that tensor on the GPU back to the CPU just do the following.
How To Perform Basic Matrix Operations With Pytorch Tensor Dev Community

Machine Learning On Gpu

Machine Learning On Gpu

How To Perform Basic Matrix Operations With Pytorch Tensor Dev Community

Nn Bilinear In Pytorch Programmer Sought

How To Perform Basic Matrix Operations With Pytorch Tensor Dev Community

Introduction To Pytorch Learn Opencv

Inconsistent Of Einsum And Torch Mm Issue 27016 Pytorch Pytorch Github
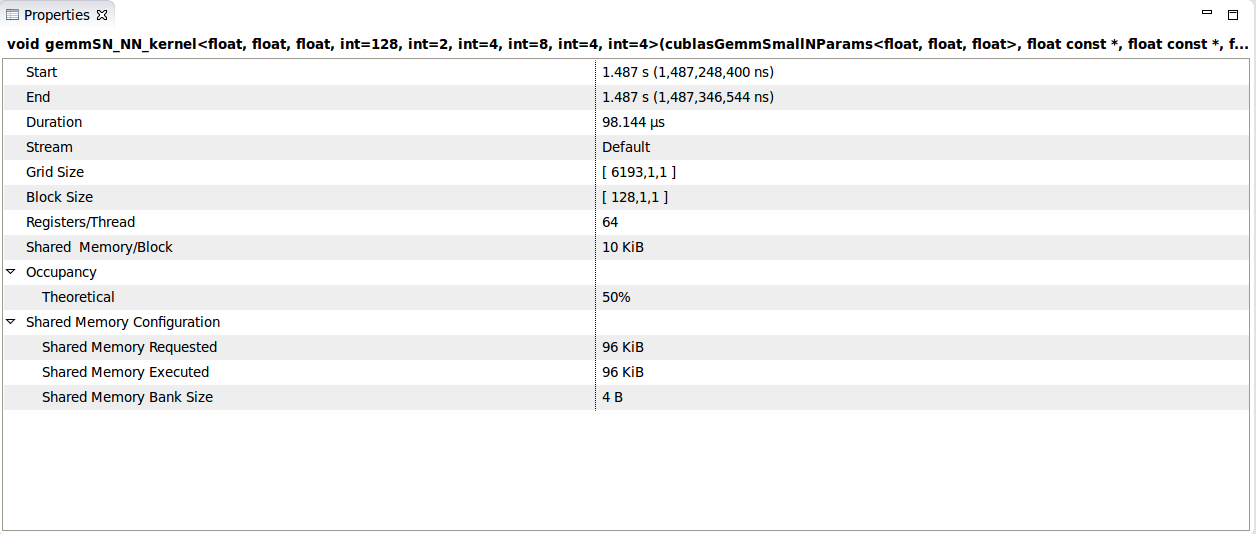
Matrix Multiplication Sometimes Can Launch Very Unoptimized Kernels Issue 16594 Pytorch Pytorch Github
Pin By Ravindra Lokhande On Technical Binary Operation Deep Learning Matrix Multiplication

Pytorch Sparse Rst At Master Pytorch Pytorch Github
How To Perform Basic Matrix Operations With Pytorch Tensor Dev Community

How To Perform Basic Matrix Operations With Pytorch Tensor Dev Community

What Is Pytorch Think About Numpy But With Strong Gpu By Khuyen Tran Towards Data Science

Matrix Multiplication Sometimes Can Launch Very Unoptimized Kernels Issue 16594 Pytorch Pytorch Github

Tutorial 2 Introduction To Pytorch Uva Dl Notebooks V1 1 Documentation

Matrix Multiplication Sometimes Can Launch Very Unoptimized Kernels Issue 16594 Pytorch Pytorch Github
Tutorial 2 Introduction To Pytorch Uva Dl Notebooks V1 1 Documentation

Inconsistent Of Einsum And Torch Mm Issue 27016 Pytorch Pytorch Github

